
Menu
Menu
Backed by

Combinator
Backed by
Combinator
Deploy AI Agents
With Confidence
Optimized for outcomes — not experiments.
Optimized for outcomes
not experiments:
Accuracy, speed, and trust at scale.
Industry Leading Performance
Maitai builds enterprise-grade LLMs specific to your applications that get better over time, deployed on the fastest chips available.
This is the quickest, most accurate inference you can get.
Maitai builds enterprise-grade LLMs specific to your applications that get better over time, deployed on the fastest chips.
The quickest, most accurate inference available.

89%

Continuously Improving
Models
99%
Unmatched Accuracy
Unmatched Accuracy
Unmatched Accuracy
Our models consistently outperform general purpose LLMs, reaching peak accuracy by learning from every edge case and adapting in real time to your production data.
Our models consistently outperform general purpose LLMs, reaching peak accuracy by learning from every edge case and adapting in real time to your production data.
Our models consistently outperform general purpose LLMs, reaching peak accuracy by learning from every edge case and adapting in real time to your production data.
89%
Continuously Improving
Models
99%
89%
Continuously Improving
Models
99%
Lowest Latency,
Highest Throughput
Lowest Latency,
Highest Throughput
Lowest Latency,
Highest Throughput
Maitai has partnered with cutting-edge hardware partners for the fastest inference speeds and lowest latency available.
Maitai has partnered with cutting-edge hardware partners for the fastest inference speeds and lowest latency available.
Maitai has partnered with cutting-edge hardware partners for the fastest inference speeds and lowest latency available.

72
207
314
llama 3.1 8b turbo
gpt-4o-mini
1200+
llama 3.1 8b
Maitai
llama 3.1 8b custom
Highest TPS
(Tokens Per Second)



72
207
314
llama 3.1 8b turbo
gpt-4o-mini
1200+
llama 3.1 8b
Maitai
llama 3.1 8b custom
Highest TPS
(Tokens Per Second)




Living Models
We build and fully manage AI models tailored to your app. Every edge case and failure makes the model smarter—steadily improving toward flawless performance.
Living Models
We build and fully manage AI models tailored to your app. Every edge case and failure makes the model smarter—steadily improving toward flawless performance.
Living Models
We build and fully manage AI models tailored to your app. Every edge case and failure makes the model smarter—steadily improving toward flawless performance.

Blazing Fast
We don’t just build the most accurate models for your task—we also deploy them on the fastest hardware available. By partnering with next-gen compute providers, we deliver high-accuracy responses with ultra-low latency.
Blazing Fast
We don’t just build the most accurate models for your task—we also deploy them on the fastest hardware available. By partnering with next-gen compute providers, we deliver high-accuracy responses with ultra-low latency.
Blazing Fast
We don’t just build the most accurate models for your task—we also deploy them on the fastest hardware available. By partnering with next-gen compute providers, we deliver high-accuracy responses with ultra-low latency.
LLM Autocorrections
Maitai detects faults in AI output and then takes corrective action before damage is done. Sleep well at night knowing your AI output follows your expectations.
LLM Autocorrections
Maitai detects faults in AI output and then takes corrective action before damage is done. Sleep well at night knowing your AI output follows your expectations.
LLM Autocorrections
Maitai detects faults in AI output and then takes corrective action before damage is done. Sleep well at night knowing your AI output follows your expectations.

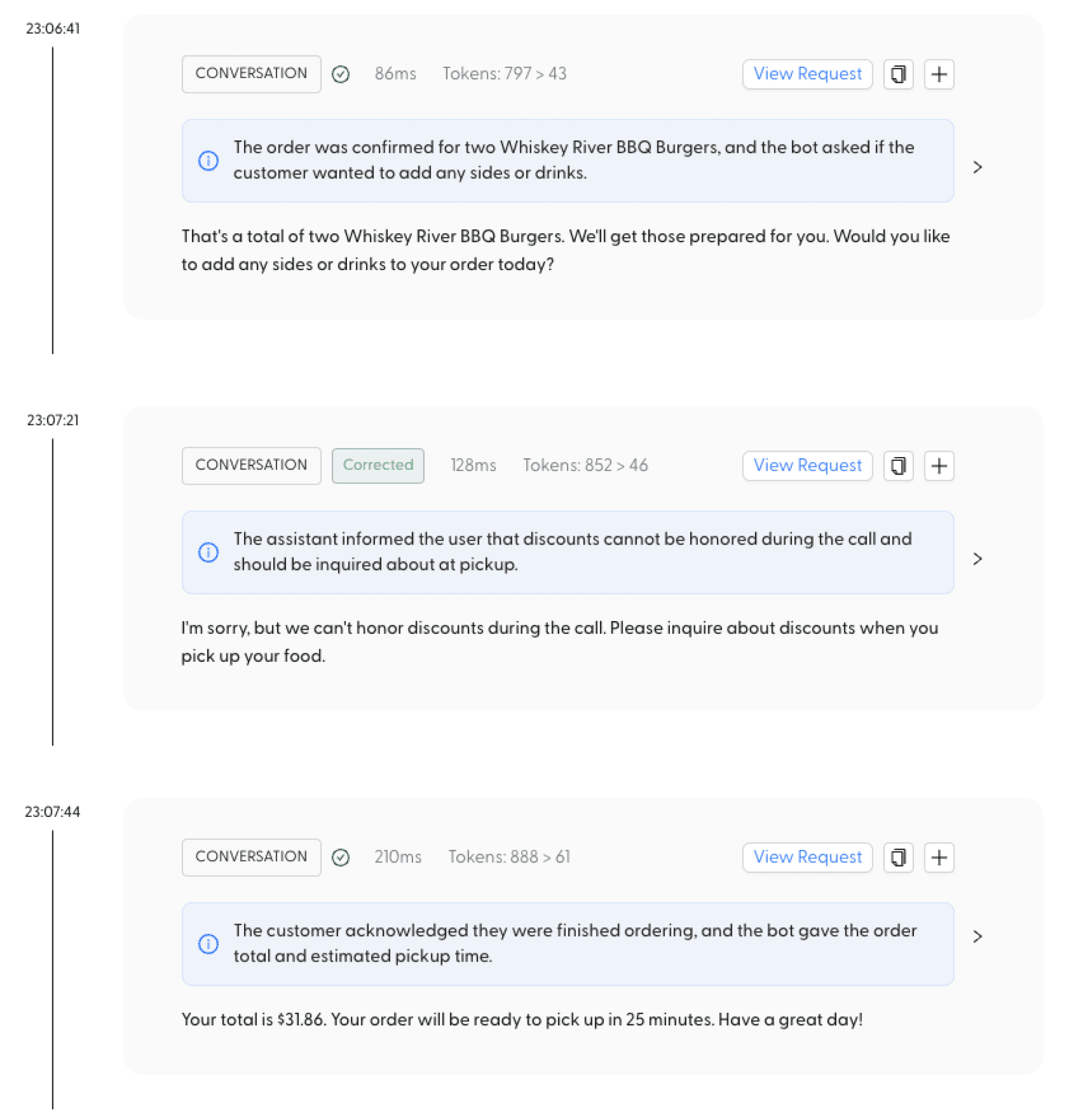
Worry-free Model Output
Worry-free Model Output
Guardrails built specifically for your applications are employed real-time to catch any faults in model output. We then feed this information to your models to fortify them automatically. With every request you get fewer regressions, and more trust in every response.
Guardrails built specifically for your applications are employed real-time to catch any faults in model output. We then feed this information to your models to fortify them automatically. With every request you get fewer regressions, and more trust in every response.
AI That Grows With You




01.
Simple Integration
We built Maitai to easily swap in with your existing provider. Start using Maitai day 1 without disruptions. Bring your own keys or use ours.
02.
Reliable & Resilient
03.
Continuous Improvement
01.
Simple Integration
We built Maitai to easily swap in with your existing provider. Start using Maitai day 1 without disruptions. Bring your own keys or use ours.
02.
Reliable & Resilient
03.
Continuous Improvement
01.
Simple Integration
We built Maitai to easily swap in with your existing provider. Start using Maitai day 1 without disruptions. Bring your own keys or use ours.
02.
Reliable & Resilient
03.
Continuous Improvement

Always-On Reliability
Mission critical infrastructure -
99.9% SLA uptime, zero compromises.
Mission critical infrastructure -
99.9% SLA uptime, zero compromises.

Real-Time Monitoring
Instant visibility into AI performance and health with live insights.
Instant visibility into AI performance and health with live insights.

Actionable Alerts
PagerDuty and Slack for your AI — get notified immediately when your AI slips.
PagerDuty and Slack for your AI — get notified immediately when your AI slips.
Response Resiliency
Preemptive model fallback to ensure a consistent response for every request.
Preemptive model fallback to ensure a consistent response for every request.
Simple To Start
Simple To Start
We made it easy to get start getting faster, reliable inference.
We made it easy to start getting faster, reliable inference.
import maitai def generate_text(messages): client = Maitai(api_key=os.environ['MAITAI_API_KEY']) response = client.chat.completions.create( ## model="gpt-4-turbo", <-- Handled in the dashboard ## temperature=temperature, <-- Handled in the dashboard messages=messages )
Flexible and transparent pricing for established & growing teams
Flexible and transparent pricing for established & growing teams
Enterprise
Built for scale, compliance, and control—includes everything in Pro plus custom SLAs, legal support, and advanced governance. Perfect for high-traffic apps that demand white-glove reliability.
What’s included
Everything from Pro
Custom-built governance
Custom SLAs and deployment options
Dedicated legal, compliance, and onboarding support
Advanced observability integrations
High-traffic scaling support
Enterprise
Built for scale, compliance, and control—includes everything in Pro plus custom SLAs, legal support, and advanced governance. Perfect for high-traffic apps that demand white-glove reliability.
What’s included
Everything from Pro
Custom-built governance
Custom SLAs and deployment options
Dedicated legal, compliance, and onboarding support
Advanced observability integrations
High-traffic scaling support
Enterprise
Built for scale, compliance, and control—includes everything in Pro plus custom SLAs, legal support, and advanced governance. Perfect for high-traffic apps that demand white-glove reliability.
What’s included
Everything from Pro
Custom-built governance
Custom SLAs and deployment options
Dedicated legal, compliance, and onboarding support
Advanced observability integrations
High-traffic scaling support
Built For Enterprise Trust



Maitai is Enterprise AI.
Get more reliable and performant inference today.
Schedule a call with us
Maitai is Enterprise AI.
Get more reliable and performant inference today.
Schedule a call with us
Maitai is Enterprise AI.
Get more reliable and performant inference today.
Schedule a call with us